The Beancount Ecosystem: A Comprehensive Analysis
Core Functionality and Philosophy of Beancount
Beancount is an open-source, double-entry accounting system that uses plain text files to record transactions. At its core, Beancount treats your ledger as a dataset defined by a simple, strict grammar. Every financial event (transactions, account openings, commodity prices, etc.) is a directive in a text file, which Beancount parses into an in-memory database of entries. This design enforces the double-entry principle: every transaction must balance debits and credits across accounts. The result is a highly transparent and auditable ledger that you can version-control, inspect, and query with ease.
Philosophy – correctness and minimalism: Beancount’s design prioritizes data integrity and simplicity. Its creator, Martin Blais, describes Beancount as “pessimistic” in assuming the user will make mistakes and thus imposes extra checks and constraints. For example, Beancount will not allow you to remove assets that were never added (preventing negative stock holdings or cash balances) and can enforce that every account is opened before use. It lacks Ledger’s concept of “virtual” or automatically balanced postings – an intentional choice to force fully balanced entries. Beancount effectively “goes hardcore” on correctness with more cross-checks than basic double-entry provides. This cautious approach appeals to users who “do not trust themselves too much” and want the software to catch their errors.
Minimal options, maximum consistency: In contrast to Ledger’s myriad of command-line flags and tuning options, Beancount opts for minimalism. There are very few global options, and none that change transaction semantics outside the ledger file. All configuration that affects accounting (like commodity cost basis methods or booking assumptions) is done in-file via directives or plugins, ensuring that loading the same file always produces the same results regardless of how reports are generated. This design avoids the complexity of Ledger’s many knobs and the subtle interactions between them. Beancount’s philosophy is that an accounting tool should be a stable, deterministic pipeline from input file to reports. It achieves this by treating the ledger as an ordered stream of directives that can be programmatically processed in sequence. Even things that Ledger treats as special syntax (like opening balances or price statements) are first-class directives in Beancount’s data model, which makes the system highly extensible.
Extensibility via plugins and query language: Beancount is implemented in Python and provides hooks to inject custom logic into the processing pipeline. Users can write plugins in Python that operate on the stream of transactions (for example, to enforce a custom rule or generate automatic entries). These plugins run as the file is processed, effectively extending Beancount’s core functionality without needing to modify the source. Beancount also includes a powerful query language (inspired by SQL) to slice and dice the ledger. The bean-query tool treats the parsed ledger as a database and lets you run analytical queries on it – for instance, summing expenses by category or extracting all transactions for a given payee. In Beancount 3.x, this querying capability was moved into a standalone beanquery package, but from a user perspective it still provides flexible reporting via SQL-like queries.
Plain text and version control: As a plaintext accounting tool, Beancount emphasizes user control and longevity of data. The ledger is simply a .beancount text file that you can edit in any text editor. This means your entire financial history is stored in a human-readable form, and you can put it in Git or another VCS to track changes over time. Users often keep their Beancount file under version control to maintain an audit trail of every edit (with commit messages describing changes). This approach aligns with Beancount’s philosophy that accounting data, especially personal or small-business finances, should be transparent and “future-proof” – not locked in a proprietary database. In Martin Blais’s own words, Beancount is a “labor of love” built to be simple, durable, and free for the community. It was first developed around 2007 and has evolved through major rewrites (v1 to v2, and now v3 in 2024) to refine its design while preserving its core philosophy of minimalism and correctness.
Tools, Plugins, and Extensions in the Beancount Ecosystem
The Beancount ecosystem has grown a rich set of tools, plugins, and extensions that enhance the core ledger functionality. These cover importing data, editing ledgers, viewing reports, and adding specialized accounting features. Below is an overview of key components and add-ons in the Beancount world:
Data Importing Utilities (Importers)
One of the most important needs for practical use is importing transactions from banks, credit cards, and other financial institutions. Beancount provides an import framework and community-contributed import scripts for this purpose. In Beancount 2.x, the built-in module beancount.ingest (with commands like bean-extract and bean-identify) was used to define importer plugins in Python and apply them to downloaded statements. In Beancount 3.x, this has been replaced by an external project called Beangulp. Beangulp is a dedicated importers framework that evolved from beancount.ingest and is now the recommended way to automate transaction import for Beancount 3.0. It allows writing Python scripts or command-line tools that read external files (like CSV or PDF statements) and output Beancount entries. This new approach decouples import logic from the Beancount core – for example, the old bean-extract command has been removed in v3, and instead your import scripts themselves produce transactions via Beangulp’s CLI interface.
Dozens of ready-made importers exist for different banks and formats, contributed by the community. There are importer scripts for institutions around the world – from Alipay and WeChat Pay in China, to various European banks (Commerzbank, ING, ABN AMRO, etc.), to US banks like Chase and Amex. Many of these are collected in public repositories (often on GitHub) or in packages like beancount-importers. For instance, the Tarioch Beancount Tools project (tariochbctools) provides importers for Swiss and UK banks and even handles crypto transaction imports. Another example is Lazy Beancount, which packages a set of common importers (for Wise, Monzo, Revolut, IBKR, etc.) and provides a Docker-based setup for easy automation. No matter which bank or financial service you use, chances are someone has written a Beancount importer for it – or you can write your own using Beangulp’s framework. The flexibility of Python means importers can handle parsing CSV/Excel files, OFX/QIF downloads, or even scraping APIs, then emit transactions in standardized Beancount format.
Editing and Editor Integration
Because Beancount ledgers are just text, users often leverage their favorite text editors or IDEs to maintain them. The ecosystem provides editor support plugins to make this experience smoother. There are extensions for many popular editors that add syntax highlighting, auto-completion of account names, and real-time error checking:
- Emacs Beancount-Mode: An Emacs major mode (
beancount-mode) is available to edit .beancount files, offering features like syntax coloring and integration with Beancount’s checker. It can even runbean-checkin the background so that errors in the ledger (like an unbalanced transaction) are flagged as you edit. - VS Code Extension: A Beancount extension on the VSCode Marketplace provides similar conveniences for Visual Studio Code users. It supports syntax highlighting, alignment of amounts, auto-completion for accounts/payees, and even on-the-fly balance checks when you save the file. It can also integrate with Fava, letting you launch the Fava web interface from within VSCode.
- Plugins or modes also exist for Vim, Atom, and other editors. For example, there’s a Tree-sitter grammar for Beancount, which powers syntax highlighting in modern editors and was even adopted in Fava’s web-based editor component. In short, whatever your editing environment, the community has likely provided a plugin to make editing Beancount files convenient and error-free.
For quick entry of transactions outside of traditional editors, there are also tools like Bean-add and mobile apps. Bean-add is a command-line tool that allows adding a new transaction via a prompt or one-liner, handling date and account suggestions. On mobile, a project called Beancount Mobile provides a simple interface to input transactions on the go (for example, recording a cash purchase from your phone). Additionally, a Beancount Telegram Bot exists to capture transactions through messaging – you can send a message with transaction details, and the bot formats it into your ledger file.
Web Frontends and Visualization Tools
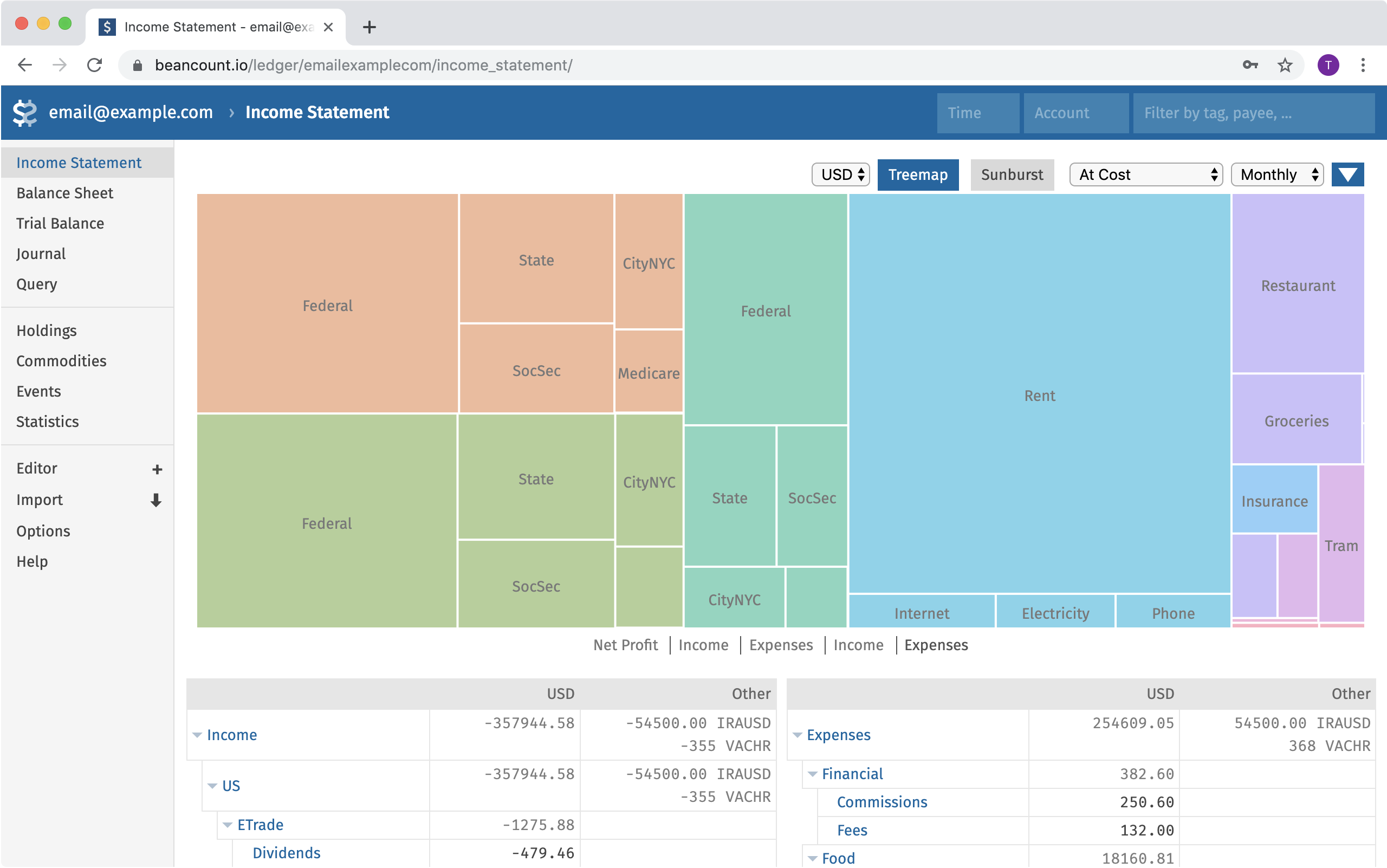
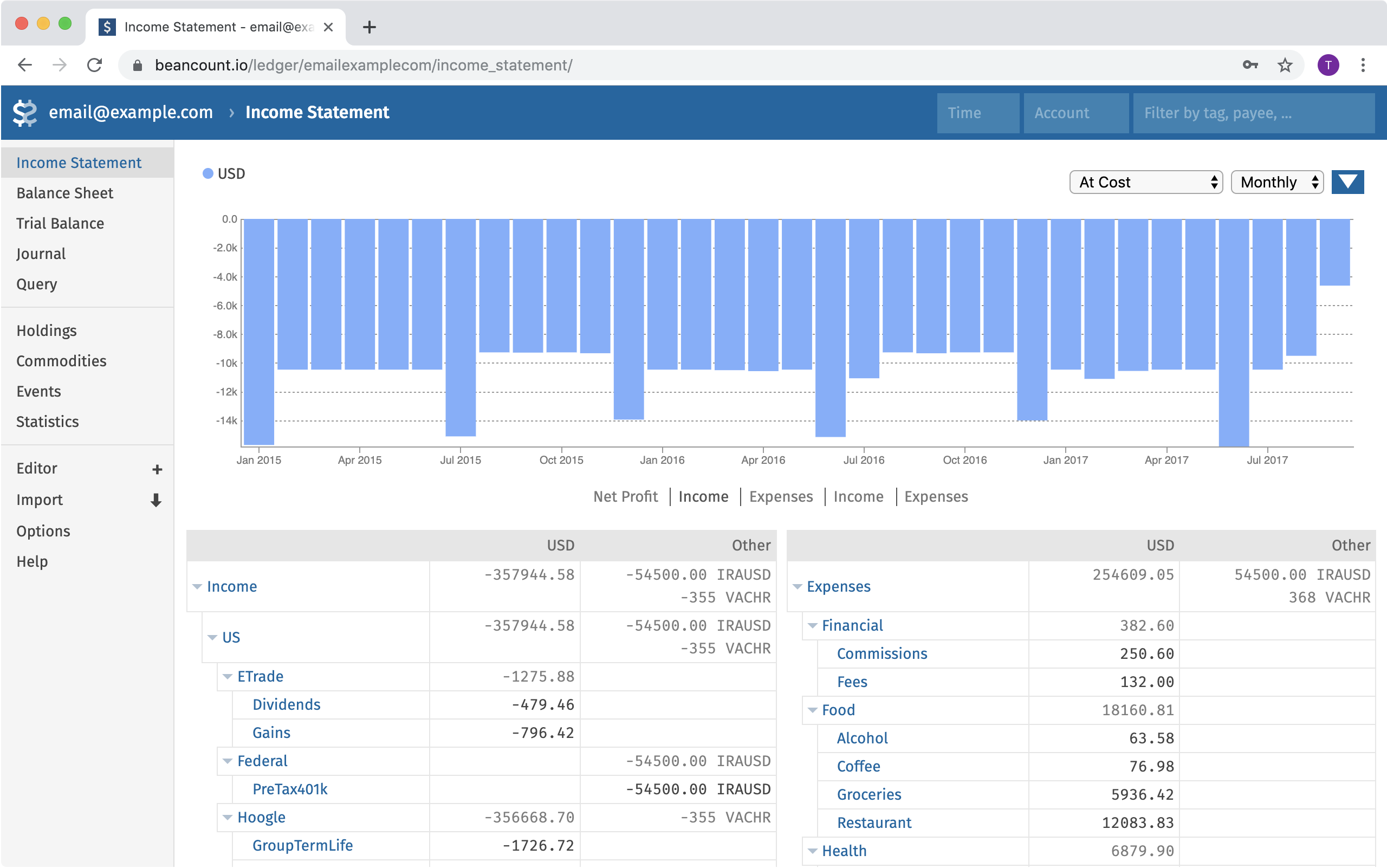
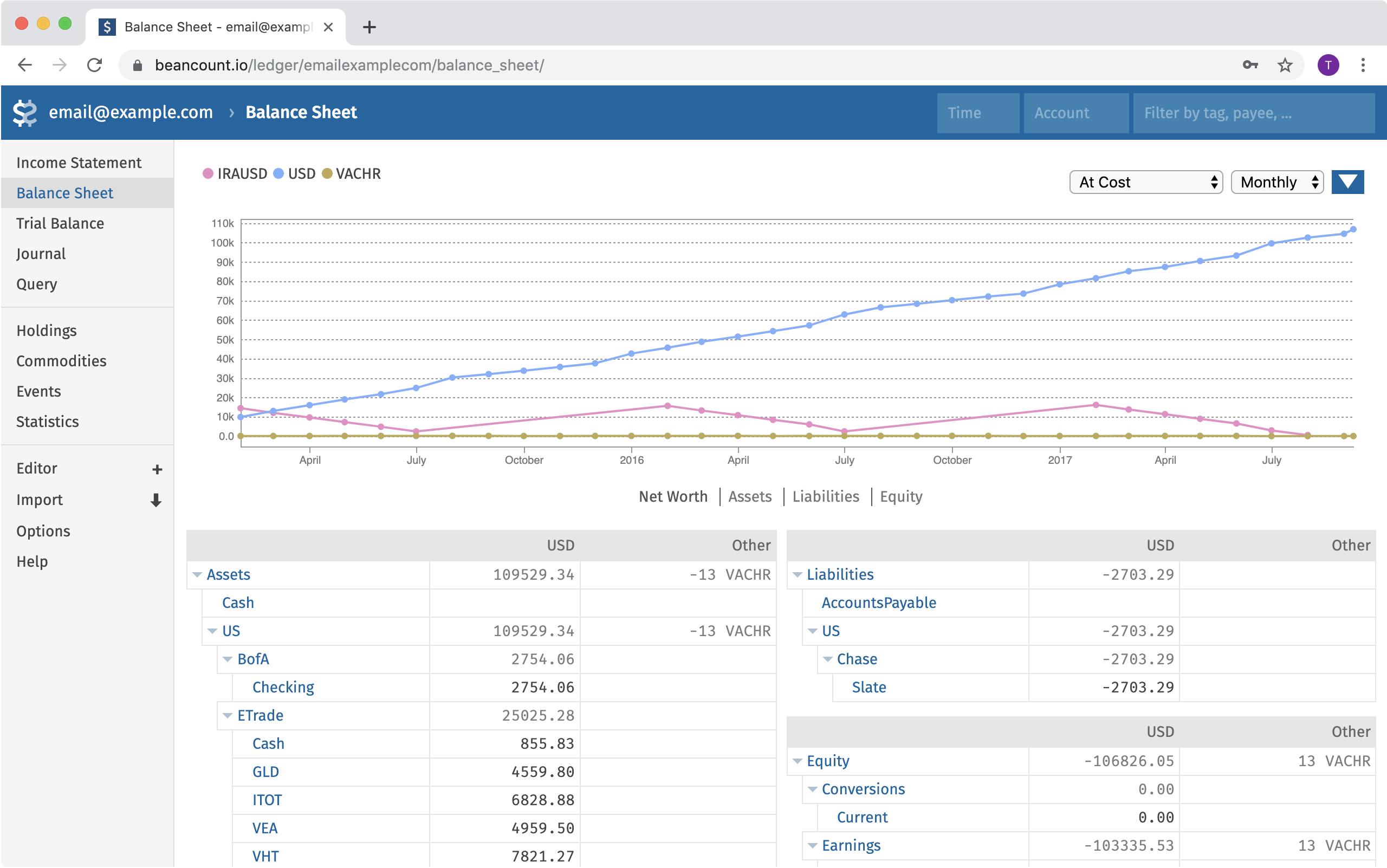
(Fava) Fava’s web interface provides an interactive dashboard for Beancount, featuring reports like an income statement with visualizations (shown here as a treemap of expenses by category) alongside tables of accounts and balances.
The flagship frontend for Beancount is Fava, a modern web interface. Fava runs as a local web app that reads your Beancount file and produces a rich interactive experience in your browser. It offers a full suite of reports: balance sheet, income statement, net worth over time, portfolio holdings, performance charts, budgets, and more – all out of the box. Users often cite Fava as a major reason for choosing Beancount over other plain-text accounting tools. With a single command (fava ledger.beancount), you can browse your finances with graphs and tables instead of text. Fava supports features like: drilling down on accounts, filtering transactions by payee or tag, a query editor (so you can run Beancount queries and see results in the browser), and even an integrated web-based editor for your ledger. It is highly usable, making plain text accounting approachable for those who prefer visual interfaces.
Under the hood, Fava is written in Python (Flask on the backend) and JavaScript (Svelte on the frontend). It has its own release cycle and is actively maintained. Notably, Fava has kept pace with Beancount’s development – for instance, Fava 1.30 added support for Beancount v3, switching to use the new beanquery and beangulp packages internally. (It still supports Beancount 2 for older ledgers.) Fava’s focus on usability includes nice touches like auto-complete in the web editor, and a sleek UI with dark mode and responsive charts. There’s also a spin-off called Fava-GTK, which packages Fava in a desktop application for GNOME/Linux users who prefer a native app feel.
Beyond Fava, other visualization and analysis options exist. Because Beancount data can be exported or queried as tables, users often leverage tools like Jupyter notebooks or Pandas for custom analysis. For example, one user describes pulling data from Beancount via the query interface into a Pandas DataFrame to prepare a custom report. There are also community-contributed scripts for specific reports – e.g. a portfolio allocation analysis tool or a process control chart for spending vs. net worth. However, for most people Fava provides more than enough reporting power without needing to write code. It even supports extensions: you can drop in Python files that add new report pages or charts to Fava. A notable extension is fava-envelope for envelope budgeting within Fava. Overall, Fava serves as the central visualization hub of the Beancount ecosystem.
Command-Line Utilities and Scripts
Beancount comes with various CLI tools (especially in the older v2 branch, some of which were trimmed in v3). These tools operate on your ledger file to check it or generate specific reports in text or HTML:
- bean-check: a validator that checks for syntax errors or accounting errors in the file. Running
bean-check myfile.beancountwill alert you to any imbalance, missing account, or other issues, and output nothing if the file is error-free. - bean-format: a formatter that tidies up your ledger by aligning numbers into neat columns, much like running a code formatter on source code. This helps keep the file clean and readable.
- bean-query: an interactive shell or batch tool to run Beancount’s query language on your ledger. You can use it to produce custom tabular reports (e.g.,
bean-query myfile.beancount "SELECT account, sum(amount) WHERE ..."). - bean-report: a versatile report generator (in v2) that can output predefined reports (balance sheet, income statement, trial balance, etc.) to the console or to files. For example,
bean-report file.beancount balanceswould print account balances. (In practice, many of these text reports have been supplanted by Fava’s nicer presentation.) - bean-web / bean-bake: an older web interface that would serve the reports on
localhostor “bake” them as static HTML files. These were mostly used before Fava became popular; bean-web provided a basic web view of the same reports bean-report could generate. In Beancount 3, bean-web has been removed (since Fava is the recommended web frontend now, offering a superior experience). - bean-example: a utility to generate an example ledger file (useful for newcomers to see a template of Beancount entries).
- bean-doctor: a debugging tool that can diagnose issues in your ledger or environment.
It’s worth noting that as of Beancount v3, many of these tools were moved out of the core project. The core Beancount package was streamlined, and tools like the query engine and importers were split into separate packages (beanquery, beangulp, etc.) for easier maintenance. For example, bean-query’s functionality is now provided by the beanquery tool which is installed separately. From a user perspective, the functionality remains available; it’s just been modularized. The Arch Linux community noted this change when updating Fava: the Fava package added dependencies on beanquery and beangulp to support Beancount 3.x. This modular approach also allows others in the community to contribute to these auxiliary tools more independently of Beancount’s release cycle.
Beancount Plugins and Extensions
A standout strength of the Beancount ecosystem is the plugin system. By adding a plugin "module.name" line in your Beancount file, you can incorporate custom Python logic that runs during the ledger processing. The community has created many plugins to extend Beancount’s capabilities:
- Data quality and rules: Examples include
beancount-balexprwhich lets you assert equations involving multiple accounts (e.g., Asset A + Asset B = Liability X), andbeancount-checkclosedwhich auto-inserts balance assertions when you close an account to ensure it nets to zero. There’s even a plugin to ensure transactions in the file are sorted by date (autobean.sorted) to catch out-of-order entries. - Automation: The
beancount-asset-transferplugin can generate in-kind transfer entries between accounts (useful for moving stocks between brokers while preserving cost basis). Another,autobean.xcheck, cross-checks your Beancount ledger against external statements for discrepancies. - Recurring transactions and budgets: The “repeat” or interpolate plugin by Akuukis allows defining recurring transactions or spreading an annual expense over months. For budgeting, the
fava-envelopeextension (used via Fava) supports envelope budgeting methodology in plain text. There’s also MiniBudget by Frank Davies – a small standalone tool inspired by Beancount to help with budgeting for personal or small business use. - Tax and reporting: Some plugins help with tax accounting, like one that classifies capital gains into short vs long-term automatically. Another (
fincen_114by Justus Pendleton) generates an FBAR report for US taxpayers with foreign accounts, illustrating how Beancount data can be leveraged for regulatory reporting. - Community plugin repositories: There are curated plugin sets such as beancount-plugins (by Dave Stephens) focusing on things like depreciation entries, and beancount-plugins-zack (by Stefano Zacchiroli) which include assorted helpers like sorting directives.
In addition to plugins, other utility tools orbiting Beancount address specific needs. For example, beancount-black is an auto-formatter similar to the Black code formatter, but for Beancount ledger files. There’s a Beancount Bot (Telegram/Mattermost) for adding transactions via chat as mentioned, and an Alfred workflow for macOS to quickly append transactions to your file. A tool named Pinto offers a “supercharged” CLI with interactive entry (like an enhanced bean-add). For those migrating from other systems, converters exist (YNAB2Beancount, CSV2Beancount, GnuCash2Beancount, Ledger2Beancount) to help bring in data from elsewhere.
In summary, the Beancount ecosystem is quite extensive. Table 1 below lists some major tools and extensions with their roles:
| Tool/Extension | Description |
|---|---|
| Fava (web interface) | Full-featured web app for viewing and editing Beancount books. Provides interactive reports (balance sheet, income, etc.), charts, and query capabilities. Major usability booster for Beancount. |
| Beangulp (import framework) | Standalone importer framework for Beancount v3, replacing older ingest module. Helps convert bank statements (CSV, PDF, etc.) into Beancount entries using plugin scripts. |
| Beanquery (query tool) | Standalone SQL-like query engine for Beancount data. Replaces bean-query in v3, allowing advanced querying of transactions and balances via a familiar SELECT-FROM-WHERE syntax. |
| Bean-check / Bean-format | Core CLI tools to validate a Beancount file (check for errors) and auto-format it for consistency. Useful for maintaining a correct and clean ledger. |
| Editor Plugins (Emacs, VSCode, Vim, etc.) | Plugins/modes that add Beancount syntax support and linting in text editors. Improve the experience of manually editing .beancount files with features like auto-complete and live error highlighting. |
| Community Importers | Collections of bank import scripts (many on GitHub) covering banks in US, EU, Asia, and more. Allow users to automatically ingest transactions from their financial institutions into Beancount. |
| Plugins (Ledger extensions) | Optional in-file plugins to enforce rules or add functionality (e.g. expense sharing, recurring entries, custom balance assertions). Written in Python and run during file processing for customization. |
| Converters (Migration tools) | Utilities to convert data from other formats into Beancount, e.g. from GnuCash or Ledger CLI to Beancount format. Facilitate adopting Beancount without starting from scratch. |
Comparison with Ledger, hledger, and Similar Systems
Beancount belongs to the family of plain text double-entry accounting tools, among which Ledger CLI (John Wiegley’s Ledger) and hledger are prominent. While all these systems share the core idea of plaintext ledger files and double-entry bookkeeping, they differ in syntax, philosophy, and ecosystem maturity. The following table highlights key differences between Beancount, Ledger, and hledger:
| Aspect | Beancount (Python) | Ledger CLI (C++) | hledger (Haskell) |
|---|---|---|---|
| Syntax & File Structure | Strict, structured syntax defined by a formal grammar (BNF). Transactions have explicit date flag "Payee" "Narration" lines and postings with quantities; all accounts must be explicitly opened/defined. No implicit postings; every transaction must balance. | More free-form syntax. Payee/description typically on the same line as the date. Allows some implicit balancing (like a single-posting transaction can imply a second posting to a default account). Account names can be used without prior declaration. Offers lots of command-line options that can affect parsing (e.g., year assumptions, commodity merge rules). | Largely follows Ledger’s syntax with minor differences. hledger is a reimplementation of Ledger’s core features in Haskell, so the journal format is very similar to Ledger’s (with some extensions and stricter parsing by default). For example, hledger is a bit more strict about dates and commodity syntax than Ledger, but not as strict as Beancount. |
| Philosophy | Conservative & Pedantic. Emphasizes catching user errors and maintaining data integrity above all. Imposes many checks (balance assertions, lot tracking) by default. Minimal configuration – “one way to do it” approach for consistency. Designed as a library with plugins for extensibility (treats ledger data as a stream to be processed, enabling custom Python logic). | Optimistic & Flexible. Trusts the user to input data correctly; fewer built-in constraints by default. Highly customizable with dozens of options and command flags to adjust behavior. Tends to be a monolithic tool with features built-in (reports, plots) and uses domain-specific language within the ledger for things like automated transactions and periodic transactions. Extensibility is typically via external scripts or the built-in query language rather than plugin APIs. | Pragmatic & Consistent. Aims to bring Ledger’s approach to a broader audience with predictable behavior. hledger defaults to more consistency (no balancing assumptions without explicit accounts) and has fewer footguns than Ledger’s most lenient modes. It has a subset of Ledger’s features (some of Ledger’s more exotic options aren’t supported), but adds some of its own (like a web interface and CSV import built-in). Emphasizes stability and correctness, but without a plugin system like Beancount’s. |
| Transactions & Balancing | Strict double-entry: every transaction must have equal total debits and credits. Does not allow unbalanced entries or placeholders (no "virtual postings" that auto-balance). Also enforces ordering independence: the ledger can be sorted by date arbitrarily because balance assertions are date-scoped, not relying on file order. Cost tracking for commodities is rigorous – when you sell assets, you must specify lots or Beancount will enforce FIFO/LIFO such that you can't remove something you didn't add. | Allows more leniency in transactions. Ledger permits "virtual" postings (using square brackets [ ] or parentheses) which don't require an explicit balancing account – often used to handle budgeting or implicit equity balancing. It's possible in Ledger to enter an incomplete transaction (omitting one side) and let Ledger infer the balancing amount. Also, Ledger does not strictly enforce lot-by-lot asset removal; it will happily subtract from an aggregate commodity balance even if specific lots weren't tracked. This makes it easier to, say, do average-cost accounting, but means Ledger won't stop you from mistakes like selling more shares than you have in a given lot. | Similar to Ledger in allowing virtual postings and implicit balancing, but with more consistent behavior. hledger enforces stricter parsing rules than Ledger but is more lenient than Beancount. |
| Inventory & Cost Basis | Precise lot tracking. Beancount attaches cost information to commodity lots (e.g., purchase of 10 shares at $100 each), and when reducing an inventory it requires matching a specific lot or using a defined strategy. It ensures capital gains and cost bases are computed correctly by design. Average-cost method isn't the default unless you explicitly write logic for it, because Beancount treats each lot distinctly to preserve accuracy. | More abstract inventory. Ledger treats commodity amounts more fluidly; by default all lots are merged in reports (it just shows total quantities). It provides options to report by lot or average cost if needed, but this is a reporting concern. Historically, Ledger did not use cost info to enforce balance in multi-commodity transactions, which could lead to subtle capital gains miscalculations. However, Ledger's flexibility lets users choose FIFO, LIFO, average, etc., at report time via command-line flags. | Similar to Ledger with flexible inventory handling. hledger can track lots when specified but doesn't enforce lot-by-lot tracking as strictly as Beancount. Capital gains calculations are available but require more manual setup. |
| Reporting & UI | Primarily through Fava (web UI) and bean-query/bean-report. Fava offers a polished web dashboard with graphs and charts, making Beancount very user-friendly for analysis. Also supports textual reports and SQL-like queries via bean-query. No official TUI (text UI), but editors/IDEs integration fills that gap. | Primarily CLI-based reporting. Ledger has many built-in report commands (balance, register, stats, etc.) that output text to the terminal. It can produce charts (ASCII or via gnuplot) and even has some add-ons for HTML reports, but it does not have an official web interface maintained as part of the project. (There have been third-party attempts at web UIs for Ledger, but none as prominent as Fava for Beancount.) For a UI, users rely on terminal or maybe GUIs like Ledger-Live (a separate project). | Offers both CLI and a simple Web UI. hledger inherits Ledger’s CLI reports (with similar commands) and additionally provides hledger-web, a basic web interface for viewing accounts and transactions in a browser. hledger-web isn’t as feature-rich as Fava, but it gives a read-only overview. hledger also has hledger-ui, a terminal curses-based interface for interactive use. |
| Extensibility & Plugins | High extensibility via Python. The plugin API allows arbitrary Python code to run during ledger processing, which means users can implement custom features without modifying core. The ecosystem of plugins (for budgeting, etc.) showcases this. Also, one can write Python scripts to use Beancount’s libraries for custom reporting. | Lower-level extensibility. Ledger can be extended by writing your own scripts that parse Ledger’s output or by using its internal query language in clever ways. It also has features like automated transactions (rules that automatically generate postings given triggers in the journal) and periodic transactions, which are kinds of built-in extensibility within the ledger file. But it does not offer an API to inject arbitrary code into the accounting engine – it’s not a library in the same way (though libledger exists for C++ developers). | Moderate extensibility. hledger deliberately omits Ledger’s automated/periodic transaction features to keep things simpler, but it provides tools like hledger-import for conversion of other formats and allows add-ons. Being written in Haskell, it’s used as a library in some projects, but writing custom plugins is not as straightforward as Beancount’s approach. Instead, hledger focuses on covering common needs (reports, web, UI) within its official toolset. |
| Community & Development | Active but primarily driven by one author (Martin Blais) and a small group of contributors. Major releases are infrequent (v2 was stable for ~6 years, then v3 in 2024). The community contributes via plugins and tools (Fava was originally a third-party project that became integral). Beancount’s mailing list and GitHub are active with discussions, and the user base has grown thanks to Fava’s appeal to non-developers. | Long history (Ledger dates back to 2003) and wide usage among engineers. Originally a one-person project (Wiegley), it saw many contributors over time. Ledger’s development has slowed in recent years; it’s stable but fewer new features (the focus has shifted to maintenance). The mailing list ledger-cli is a hub for all plaintext accounting discussions (including Beancount and hledger). Many tools and scripts around Ledger exist, but the ecosystem is not as unified (no single “Ledger GUI”, etc., though multiple independent efforts exist). | Growing community, with Simon Michael leading hledger’s development. hledger has annual releases and steady improvements, often tracking Ledger feature changes but also forging its own path. It enjoys popularity among users who want Ledger’s power with more predictability. The community tends to overlap with Ledger��’s (plaintextaccounting.org covers both). hledger’s ecosystem includes add-ons like hledger-flow (for workflow automation) and it benefits from being written in Haskell (attracting those in that community). |
In summary, Beancount differentiates itself with its emphasis on strictness, plugin-based extensibility, and a user-friendly web interface. Ledger remains the classic, highly flexible tool favored by command-line purists and those who need ultimate speed (Ledger’s C++ engine is very fast on huge files). hledger provides a middle ground – much of Ledger’s functionality with a bit more structure and an officially supported (if simple) web UI. All three share the advantages of plain text accounting (auditability, Git versioning, plain data), but Beancount’s ecosystem (especially with Fava) has arguably made it more accessible to the average user in recent years. On the flip side, Ledger/hledger users sometimes prefer their relative simplicity in setup (no Python needed) and long-proven stability. Ultimately, choosing between them comes down to personal preference: those who value rigorous correctness and a rich ecosystem often lean toward Beancount, whereas those who want lean, terminal-focused tooling might stick with Ledger or hledger.
Usage Scenarios for Beancount
Beancount is versatile enough to be used for personal finance tracking as well as (in some cases) small business accounting. Its core double-entry approach is the same in both scenarios, but the scale and specific practices can differ.
Personal Finance
Many Beancount users employ it to manage their individual or household finances. A typical personal finance setup in Beancount might include accounts for checking and savings, credit cards, investments, loans, income categories (salary, interest, etc.), and expense categories (rent, groceries, entertainment, etc.). Users record day-to-day transactions either manually (entering receipts, bills, etc.) or by importing from bank statements using the importer tools discussed earlier. The benefits Beancount brings to personal finance include:
- Consolidation and Analysis: All your transactions can live in a single text file (or a set of files) that represents years of financial history. This makes it easy to analyze long-term trends. With Beancount’s query language or with Fava, you can answer questions like “How much did I spend on travel in the past 5 years?” or “What’s my average monthly grocery bill?” in seconds. One user noted that after switching to Beancount, “analysis of financial data (spending, giving, taxes, etc.) is trivial” either through Fava or by querying the data and using tools like Pandas. In essence, your ledger becomes a personal financial database you can query at will.
- Budgeting and Planning: While Beancount doesn’t force a budgeting system, you can implement one. Some users do envelope budgeting by creating budget accounts or using the
fava-envelopeplugin. Others simply use periodic reports to compare spending to targets. Because it’s plain text, integrating Beancount with external budgeting tools or spreadsheets is straightforward (exporting data or using CSV outputs from queries). - Investments and Net Worth Tracking: Beancount excels at tracking investments thanks to its robust handling of cost bases and market prices. You can record buys/sells of stocks, crypto, etc., with cost details, and then use
Pricesdirectives to keep track of market value. Fava can show a net worth over time chart and portfolio breakdown by asset class. This is hugely useful for personal wealth management – you get insights similar to what commercial tools like Mint or Personal Capital provide, but fully under your control. Multi-currency handling is also built-in, so if you hold foreign currencies or crypto, Beancount can track those and convert for reporting. - Reconciliation and Accuracy: Personal finance often involves reconciling with bank statements. With Beancount, one can regularly reconcile accounts by using balance assertions or the documents feature. For example, every month you might add a
balance Assets:Bank:Checking <date> <balance>entry to confirm your ledger matches the bank’s statement at month-end. Thebean-checktool (or Fava’s error display) will alert you if things don’t line up. One user mentions doing a monthly reconciliation of all accounts, which “helps catch any unusual activity” – a good personal finance hygiene practice that Beancount facilitates. - Automation: Tech-savvy individuals have automated large parts of their personal finance workflow with Beancount. Using importers, cron jobs, and maybe a bit of Python, you can set up your system so that, for instance, every day your bank transactions are fetched (some use OFX or APIs) and appended to your Beancount file, categorized by rules. Over time, your ledger becomes mostly auto-updated, and you just review and tweak as needed. A community member on Hacker News shared that after 3 years, their Beancount books were “95% automatic”. This level of automation is possible because of Beancount’s plain text openness and scripting capabilities.
Personal finance users often choose Beancount over spreadsheets or apps because it gives them complete ownership of the data (no reliance on a cloud service that might shut down – a concern as Mint was discontinued, for example) and because the depth of insight is greater when you have all your data integrated. The learning curve is non-trivial – one must learn basic accounting and the Beancount syntax – but resources like the official documentation and community tutorials help newcomers get started. Once set up, many find that it brings peace of mind to have a clear, trustworthy picture of their finances at all times.
Small Business Accounting
Using Beancount for a small business (or nonprofit, club, etc.) is less common than personal use, but it is certainly possible and some have done it successfully. Beancount’s double-entry framework is in fact the same system that underpins corporate accounting, just without some of the higher-level features that dedicated accounting software provides (like invoicing modules or payroll integrations). Here’s how Beancount can fit into a small business context:
- General Ledger and Financial Statements: A small business can treat the Beancount file as its general ledger. You would have asset accounts for bank accounts, accounts receivable, maybe inventory; liability accounts for credit cards, loans, accounts payable; equity for owner’s capital; income accounts for sales or services; and expense accounts for all business expenses. By maintaining this ledger, you can produce an Income Statement (Profit & Loss) and Balance Sheet at any time using Beancount’s reports or queries. In fact, Beancount’s built-in reports or Fava can generate a balance sheet and P&L in seconds that are perfectly in line with accounting principles. This can be sufficient for a small operation to assess profitability, financial position, and cash flow (with a bit of querying for cash flow, since direct cash flow statements aren’t built-in but can be derived).
- Invoices and A/R, A/P: Beancount does not have a built-in invoicing system; users would typically handle invoicing outside (e.g., create invoices in Word or an invoice app) and then record the results in Beancount. For example, when you issue an invoice, you’d record an entry debiting Accounts Receivable and crediting Income. When the payment comes, you debit Cash/Bank and credit Accounts Receivable. This way, you can keep track of outstanding receivables by looking at the balance of the A/R account. The same applies to bills (A/P). While it’s more manual than specialized accounting software (which might send reminders or integrate with emails), it is perfectly doable. Some users have shared templates or workflows on how they manage invoices with Beancount and ensure they don’t miss open invoices (for instance, by using metadata or custom queries to list unpaid invoices).
- Inventory or Cost of Goods Sold: For businesses selling products, Beancount can track inventory purchases and sales, but it requires disciplined entries. You might use the
Inventoryand cost accounting features: purchasing inventory increases an asset account (with cost attached to the items), selling it moves cost to an expense (COGS) and records revenue. Because Beancount insists on matching lots, it will enforce proper reduction of inventory with the correct cost, which can actually ensure your gross profit calculations are accurate if done right. However, there’s no automated SKU tracking or anything – it’s all at the financial level (quantity and cost). - Payroll and Complex Transactions: Beancount can record payroll transactions (salary expense, tax withholdings, etc.), but calculating those figures might be done externally or via another tool, then just booked into Beancount. For a very small business (say one or two employees), this is manageable. You’d, for example, record a single journal entry per pay period that splits out wages, tax withheld, employer tax expense, cash paid, etc. Doing this manually is similar to how one might do it in QuickBooks journal entries – it requires knowledge of what accounts to hit.
- Multi-user and Audit: One challenge in a business setting is if multiple people need to access the books or if an accountant needs to review them. Since Beancount is a text file, it’s not multi-user in real-time. However, hosting the file in a Git repository can enable collaboration: each person can edit and commit, and differences can be merged.
- Regulatory compliance: For tax filing or compliance, Beancount’s data can be used to generate the necessary reports, but it may require custom queries or plugins. We saw an example of a community plugin for Indian government compliance reporting, and one for FinCEN FBAR reporting. This shows that, with effort, Beancount can be adapted to meet specific reporting requirements. Small businesses in jurisdictions with simple requirements (cash accounting, or basic accrual) can certainly maintain books in Beancount and produce financial statements for tax returns. However, features like depreciation schedules or amortization might need you to write your own entries or use a plugin (Dave Stephens’ depreciation plugins help automate that for instance). There isn’t a GUI to “click depreciate asset” as in some accounting software; you’d encode the depreciation as transactions (which in a way demystifies it – everything is an entry you can inspect).
In practice, many tech-oriented small business owners have used Beancount (or Ledger/hledger) if they prefer control and transparency over the convenience of QuickBooks. A Reddit discussion noted that for standard small-business accounting with a limited volume of transactions, Beancount works fine. The limiting factor is usually the comfort level – whether the business owner (or their accountant) is comfortable with a text-based tool. One advantage is cost: Beancount is free, whereas accounting software can be costly for a small business. On the other hand, lack of official support and the DIY nature means it’s best suited for those who are both the business owner and somewhat technically inclined. For freelancers or sole proprietors with programming skills, Beancount can be an attractive choice to manage finances without relying on cloud accounting services.
Hybrid approaches are also possible: some small businesses use an official system for invoices or payroll, but periodically import the data into Beancount for analysis and archival. This way they get the best of both worlds – compliance and ease for day-to-day operations, plus the power of Beancount for consolidated insight.
In summary, Beancount can handle small business accounting, provided the user is willing to manually manage things that commercial software automates. It ensures a high degree of transparency – you deeply understand your books because you’re writing them – and for a diligent user, it can produce impeccable books. Both personal and business users benefit from Beancount’s core strengths: a reliable accounting engine, complete audit trail, and flexibility to adapt to unique scenarios (via scripting and plugins). Whether it’s tracking a household budget or a startup’s finances, Beancount offers a toolkit to do it with precision and openness.
Community and Development Activity
Beancount has a dedicated community and a development story that reflects its open-source, niche-but-passionate nature. Below are key points about its community, maintainers, and related projects:
-
Project Maintenance: Beancount’s primary author is Martin Blais, who began the project around 2007 and has shepherded it through multiple versions. Development for a long time was largely a one-man effort (aside from community contributions of patches). Martin’s philosophy was to build an accounting tool “useful to me first, as well as for others, in the simplest, most durable manner”. This personal motivation kept the project going as a labor of love. As of 2025, Martin Blais is still the lead maintainer (his name appears on commits and he answers questions on the mailing list/issue tracker), but the ecosystem around Beancount has many other contributors in their respective projects.
-
GitHub and Repositories: The source code is hosted on GitHub under the
beancount/beancountrepository. The project is GPL-2.0 licensed and has attracted a modest number of contributors over the years. In mid-2024, Beancount Version 3 was officially released as the new stable branch. This release involved splitting out some components: for example, the beangulp repo (for importers) and beanquery repo (for the query tool) are part of thebeancountGitHub organization now, maintained somewhat independently. The main Beancount repo focuses on the core accounting engine and file parser. As of 2025, Beancount’s GitHub shows active issue discussions and some ongoing development – though not high volume, issues and pull requests trickle in, and occasional updates are made to fix bugs or refine features. -
Fava Development: Fava, the web interface, started as a separate project (created by Dominic Aumayr, who copyrighted it in 2016). It has its own community of contributors and is also on GitHub under
beancount/fava. Fava’s maintainers and contributors (e.g. Jakob Schnetz, Stefan Otte, and others in recent years) have been actively improving the interface, with releases every few months. Fava’s Gitter chat (linked on the Fava docs) and GitHub issue tracker are places where users and devs discuss new features or bugs. The project welcomes contributions, evidenced by a CHANGELOG note thanking multiple community members for their PRs. Fava’s close alignment with Beancount’s development (such as quickly adding support for Beancount v3 and new beanquery syntax) indicates good collaboration between the two projects. -
Mailing Lists and Forums: Beancount has an official mailing list (previously on Google Groups, titled “Beancount” or sometimes discussed on the general Ledger list). This mailing list is a treasure trove of knowledge – users ask questions about how to model certain scenarios, report bugs, and share tips. Martin Blais is known to respond on the mailing list with detailed explanations. In addition, the broader Plain Text Accounting community overlaps heavily. The Ledger CLI mailing list often entertains questions about Beancount as well, and there is a forum at plaintextaccounting.org and a subreddit r/plaintextaccounting where Beancount topics come up frequently. Users on these platforms discuss comparisons, share personal setups, and help newcomers. The general tone of the community is very cooperative – Beancount users often help Ledger users and vice versa, recognizing that all these tools have similar goals.
-
Chat Groups: Besides mailing lists, there are chat channels like the Plaintext Accounting Slack/Discord (community-organized) and the Fava Gitter. These are less formal, more real-time ways to get help or discuss features. For example, one might hop on the Slack to ask if anyone has an importer for a specific bank. There is also a Matrix/IRC channel (historically #ledger or #beancount on IRC) where some long-time users idle. While not as populous as communities for mainstream software, these channels have knowledgeable folks who can often answer obscure accounting questions.
-
Contributors and Key Community Members: A few names stand out in the Beancount community:
- “Redstreet” (Red S): A prolific contributor who has written many plugins (like
beancount-balexpr,sellgains, and others) and often provides support. They also maintain a set of importer scripts and a tool calledbean-downloadto fetch statements. - Vasily M (Evernight): Author of some importer frameworks and plugins like
beancount-valuation, and contributions to Fava regarding investments. - Stefano Zacchiroli (zack): A Debian developer who created the beancount-mode for Emacs and his own plugin repo. He has advocated for plaintext accounting in academic settings as well.
- Simon Michael: While primarily the lead of hledger, he runs plaintextaccounting.org which includes Beancount. This cross-pollination helped bring Beancount to the attention of Ledger/hledger users.
- Frank hell (Tarioch): Contributor of the Tarioch Beancount Tools, a major set of importers and price fetchers especially for European institutions.
- Siddhant Goel: A community member who blogs about Beancount (for example, his guide on migrating to v3) and maintains some importers. His blog posts have helped many new users.
These and many others contribute code, documentation, and help on forums, making the ecosystem vibrant despite its relatively small size.
- “Redstreet” (Red S): A prolific contributor who has written many plugins (like
-
GitHub Stats and Forks: Beancount’s GitHub repo has accumulated a few hundred stars (indicating interest) and forks. Notable forks of Beancount itself are rare – there isn’t a well-known divergent fork that tries to be “Beancount but with feature X”. Instead, when users wanted something different, they either wrote a plugin or used another tool (like hledger) rather than fork Beancount. One could consider hledger a kind of fork of Ledger (not Beancount) and Beancount itself an independent re-imagining of Ledger’s ideas, but within Beancount’s repo there aren’t big splinter projects. The community has generally coalesced around the main repo and extended it via the plugin interface instead of fragmenting the codebase. This is likely because Martin Blais was open to external contributions (his docs even have a section acknowledging external contributions and modules) and the plugin architecture made it unnecessary to maintain a fork for most new features.
-
Community Resources: There are several high-quality resources for learning and using Beancount created by the community:
-
The Beancount documentation on GitHub Pages (and the source Google Docs that Martin maintains) – very comprehensive, including theory on accounting and how Beancount implements it.
-
Numerous blog posts and personal notes – e.g., LWN.net had an article “Counting beans… with Beancount”, and many personal blogs (as listed in Awesome Beancount’s “Blog Posts” section) share experiences and tips. These help build knowledge and attract new users.
-
Talks and presentations: Beancount has been presented at meetups and conferences (for instance, a PyMunich 2018 talk on managing finances with Python/Beancount). Such talks introduce the tool to broader audiences and often spark interest on forums like Hacker News.
-
-
Notable Related Projects: Apart from Fava, some other projects related to Beancount have their own communities:
- Plain Text Accounting site – maintained by Simon Michael, it aggregates info on all such tools and has a forum where people share usage for various tools including Beancount.
- Financial tooling integration: Some users integrate Beancount with business intelligence tools or databases. For example, one Google Groups thread details using PostgreSQL with Beancount data via custom functions. While not mainstream, it shows the community’s experimental spirit in pushing Beancount’s capabilities (e.g., to handle very large datasets or complex queries beyond the built-in).
In summary, Beancount’s community, while smaller than those of big open-source projects, is highly engaged and knowledgeable. The project enjoys a steady stream of improvements and very helpful support channels. The collaborative ethos (sharing importers, writing plugins, answering questions) means that a newcomer in 2025 can rely on extensive prior work and community wisdom to set up their accounting system. Development is active in the ecosystem sense – Fava releases, plugin development, etc. – even if the core’s changes are more occasional. The ecosystem’s growth (as evidenced by the Awesome Beancount list of dozens of tools) speaks to a healthy community making Beancount ever more capable.
Recent Developments and Upcoming Features
As of 2025, the Beancount ecosystem has seen significant developments in the past couple of years, and there are ongoing discussions about future enhancements. Here are some noteworthy recent developments and a glimpse of what might be coming:
-
Beancount 3.0 Release (2024): After a long period of Beancount 2.x being the standard, version 3 was officially released in mid-2024. This was a major milestone because v3 represents a simplification and modernization of the codebase. Martin Blais had envisioned v3 as a chance to “rearrange and simplify” the system further. While it was originally thought to be a big rewrite, in practice the update for users was not too disruptive. The main changes were under the hood: a new parser, some performance improvements, and the extraction of optional components out of the core. The release was rolled out gradually (v3 had been in beta since 2022, but by July 2024 it became the recommended stable version). Users like Siddhant Goel reported that migrating from 2.x to 3.x was “mostly uneventful” with only a few workflow changes.
-
Modularization – tools moved to separate packages: One of the big changes with Beancount 3 is that many tools that used to live in the monolithic repository were spun off. For example, bean-query is now provided by the
beanquerypackage, and beancount.ingest was replaced by thebeangulppackage. Commands likebean-extractandbean-identify(for imports) were removed from core Beancount. Instead, the philosophy is to use standalone scripts for importing. This means that if you upgrade to v3, you’d installbeangulpand run importer scripts (each importer is basically a small program) rather than having a centralbean-extractconfig file. Similarly, queries are executed viabeanquerywhich can be installed and updated independently of Beancount core. This modular approach was designed to make maintenance easier and encourage community contributions. It also slimmed down Beancount’s core, so the core focuses purely on parsing and accounting logic, while ancillary functionality can evolve separately. From a user perspective, after upgrading, one has to adjust commands (e.g., usebean-queryfrom beanquery, or use Fava which abstracts this anyway). Fava’s changelog explicitly notes these changes: Fava now depends on beanquery and beangulp, and it handles import workflows differently for Beancount 3 vs 2. -
Performance Improvements: Performance was one motivation for revisiting Beancount’s design. The v3 plan (as outlined in Martin’s “V3 goals” document) included optimizing the parser and possibly making the loading process faster and less memory-intensive. By 2025, some of these improvements have materialized. Anecdotally, users with very large ledgers (tens of thousands of transactions, or lots of stock trades) have reported better performance with the latest version. For instance, a user dealing with “microinvestment transactions” who faced performance issues noted these concerns on the Google Group – this kind of feedback likely informed v3. The new parser is more efficient and written in a clearer way, which could be extended in the future. Additionally, Fava 1.29 moved to a more efficient file-watching mechanism (using the
watchfileslibrary) to improve responsiveness when the ledger changes. Looking forward, the community might explore incremental parsing (only re-processing changed parts of the file instead of everything) to handle large ledgers more quickly – this was hinted in the docs as “Beancount server / incremental booking” idea. -
Investment Tracking Enhancements: There’s been ongoing work to make investment and portfolio reporting better. For example, handling of average cost basis vs. FIFO was discussed at length. While Beancount enforces lot matching, some users prefer average cost for certain jurisdictions. A proposal and discussion exist about making cost basis booking more flexible (possibly via a plugin or option). By 2025, no built-in switch for average cost is present, but the groundwork in v3 (the booking redesign) makes it easier for plugins to implement. A community plugin “Gains Minimizer” was released that can suggest which lots to sell to minimize taxes, showing the kind of advanced tooling being built around investments. Fava, too, added features like a portfolio summary extension (with rate of return calculations). In terms of upcoming features, one can expect more in this domain: possibly automated portfolio rebalancing suggestions or risk analysis, likely as external tools that read Beancount data (since the data is all there).
-
New Plugins and Extensions: The plugin ecosystem continuously grows. Recent notable additions include:
- Budget reporting tools – e.g., a simple CLI budget reporter if one doesn’t use Fava’s UI.
- Encryption and security – the fava-encrypt setup, allowing Fava to be hosted online with the ledger encrypted at rest, was introduced, addressing the concern of self-hosting your finances.
- Quality-of-life plugins – like
autobean-format(a new formatter that can handle more corner cases by parsing and reprinting the file), andbeancheckintegration in editors (flymake for Emacs).
Looking ahead, the community is likely to continue filling gaps via plugins. For example, we might see more tax-related plugins (some users have shared scripts for things like computing wash sales or specific local tax reports).
-
Potential Upcoming Features: Based on discussions on the issue tracker and mailing list, a few ideas are on the horizon (though not guaranteed):
- Time Resolution: Currently, Beancount only tracks dates (no timestamps) for transactions. There have been questions about adding time (for stock trades or ordering of same-day transactions). Martin Blais explicitly decided that sub-day timestamps were out of scope to keep things simple. This is unlikely to change soon – so upcoming versions probably will not add time resolution, sticking to the stance that if you need time, you incorporate it into narration or an account.
- Enhanced GUI editing: Fava is continuously improving its editing capabilities. A possibility is a more full-featured web editor (with auto-suggest, maybe a form-based entry for new transactions). The groundwork using tree-sitter in Fava’s editor was laid. We might see Fava become not just a viewer but a more powerful editor, reducing the need to open a text editor at all for many tasks.
- Better multi-ledger support: Some users maintain multiple Beancount files (for different entities or for splitting personal vs business). Right now, including files is possible but had limitations (plugins in included files, etc.). A recent plugin
autobean.includewas created to safely include external ledgers. In the future, we might see first-class support for multi-file setups – perhaps a concept of a Beancount “project” with multiple files (this is hinted by features like the VSCode extension’sbeancount.mainBeanFilesetting). This would help those running multi-entity bookkeeping or wanting to modularize their ledger. - Realtime or Incremental Computation: As ledgers grow, the ability to recompute reports quickly becomes important. There is an idea of a Beancount server that stays running and updates results as transactions change. This could manifest as an optimization in Fava or a daemon that editor plugins can query. Perhaps a future Fava release will leverage a continuously running Beancount process to make the UI more responsive for huge ledgers.
- Fund Accounting / Non-profit features: There was an enhancement proposal about fund accounting in Beancount. Non-profit organizations have accounting needs (restricted vs unrestricted funds) that could potentially be modeled with Beancount’s tag or account hierarchy. The discussion didn’t yet lead to built-in features, but if more non-profits pick up Beancount, this could drive new capabilities (maybe just documented best practices or plugins for fund balance tracking).
-
Long-Term Outlook: Martin Blais hinted that he sees the future of Beancount in making the core more of an engine and moving more functionality to plugins. This is consistent with what we see (modularization in v3). So, an “upcoming feature” in philosophical terms is greater extensibility – possibly even allowing plugins to define new directive types or extend syntax in controlled ways. If that happens, Beancount’s core might remain relatively small and stable, while the ecosystem delivers most new functionality as add-ons. This could lead to a plugin marketplace or more centralized listing of plugins so users can pick and choose (the Awesome Beancount list is a start at that).
In conclusion, the Beancount ecosystem in 2025 is active and evolving. The release of Beancount 3.0 was a major recent event, ensuring the project’s foundation is solid for the future. Improvements in performance, tooling, and usability (especially via Fava) have continued to lower the barrier to entry. While Beancount remains a tool that requires some expertise, it is far more approachable now than a few years ago, thanks to these developments. Upcoming features will likely focus on refining the experience – faster performance, better integrations, and specialized extensions – rather than drastic changes to the core philosophy. The community’s trajectory suggests that Beancount will continue to mature as the centerpiece of plain text accounting, striking a balance between the austere power of double-entry bookkeeping and the convenience of modern software. As one user quipped on Hacker News, plain text accounting gives you “super powers” in understanding your finances – and Beancount’s recent and future improvements aim to make those super powers easier to wield for everyone.
Sources: Beancount documentation and repository; Fava documentation; “A Comparison of Beancount and Ledger” by Martin Blais; Awesome Beancount resource list; User experiences and community reports;